Jubatus(ユバタスと読む。チーターという意味)はNTTとPFIが一緒に開発した国産のソフトウエアで NTTのホームページのVol.3 「Jubatus(ユバタス)」 ビッグデータを「大量に」「素早く」「深く」解析できる仕組みには ↓のように記載されています。
「Jubatus」は、「Hadoop」にはない「リアルタイム処理」「オンライン機械学習」の2点を兼ね備えており、 素早いレスポンスが求められる場面でより高度なデータ分析を行うことが可能となっている。 また、メールのスパムフィルタ等で活用されている分類機能や、後述のサーバの消費電力推定等で利用できる回帰機能、 またレコメンデーション機能に用いられる近傍探索機能といった、世の中で広く用いられているアルゴリズムに対応している。
なんか読んでるだけでワクワクしてきますね。
来週、第3回 Jubatus ハンズオン EC2で分散実行編という勉強会があって、 それに参加申込みするのに、過去のハンズオンの第1回 Jubatus ハンズオンを理解してるの前提的な。 やろうやろうと思ってたのですが、なかなかアレで、、 ようやく第1回のハンズオン終わったので、第3回に申し込もうとってたら、キャンセル待ちっていう…orz ■ イントロダクション まずはPDFのイントロダクションを読んでみます。 ↓の部分を読んでて、コレ使いこなせたら前職の時のアレとかアレとかウマいことやれたんじゃないかなって思ったりとか。
Jubatus は NTT 研究所と Preferred Infrastructure が共同開発し、オープンソースとして公開している機械学習の ツールです。先ほど書いたような分類問題のみならず、回帰、レコメンド、異常検知など、様々な機械学習の問題 を扱うことができます。
Jubatus のもう一つの大きな特徴として、分散環境で動かすことができます。機械学習の技術を使うときに扱う データが大量になる場合があります。Jubatus は複数の計算機に分散して学習を行うことができるように作られて います。
Jubatus は機械学習技術の中でも、 オンライン学習 と呼ばれる種類の技術にのみフォーカスしています。従 来はデータを貯めこんでから学習を行うバッチ学習という方法が主流でした。近年は、データを貯めこまず、次々 にやってくるデータを使って逐次的に学習する手法の研究が盛んになっています。それがバッチ処理と対比して オンライン学習と呼ばれるアプローチです。
■ セットアップ&実行
↓に沿って環境をセットアップしていきます。
http://download.jubat.us/event/handson_01/setup/
VirtualBoxにJubatusのハンズオンの環境が入ったイメージをロードして、
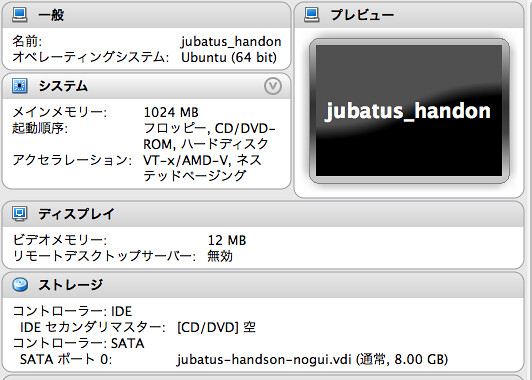 起動して稼働を確認後、
起動して稼働を確認後、
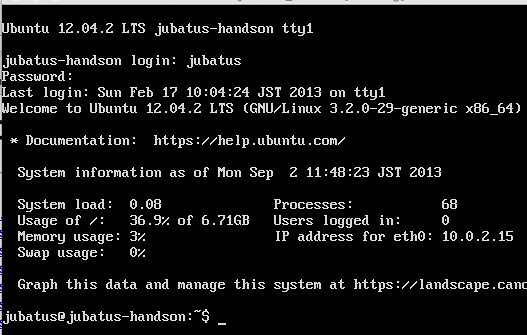 ホストOSからSSHとJubatusのプロトコルでアクセスするように設定します。
ホストOSからSSHとJubatusのプロトコルでアクセスするように設定します。
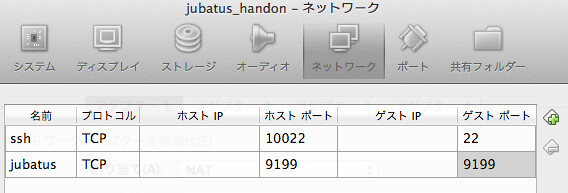 sshでホストOSから接続して、分類用のコマンドである jubaclassifier を叩いてみます。ほうほうって感じ。
sshでホストOSから接続して、分類用のコマンドである jubaclassifier を叩いてみます。ほうほうって感じ。
jubatus@jubatus-handson:~$ jubaclassifier can't start standalone mode without configpath specified usage: jubaclassifier [options] ... options: -p, --rpc-port port number (int [=9199]) -b, --listen_addr bind IP address (string [=]) -B, --listen_if bind network interfance (string [=]) -c, --thread concurrency = thread number (int [=2]) -t, --timeout time out (sec) (int [=10]) -d, --datadir directory to save and load models (string [=/tmp]) -l, --logdir directory to output logs (instead of stderr) (string [=])
サーバー起動用の設定JSONを食わせます。
jubatus@jubatus-handson:~$ jubaclassifier -f /opt/jubatus/share/jubatus/example/config/classifier/pa1.json I0902 16:09:46.966070 1678 server_util.cpp:196] starting jubaclassifier 0.4.0 RPC server at 10.0.2.15:9199 pid : 1678 user : jubatus mode : standalone mode timeout : 10 thread : 2 datadir : /tmp logdir : loglevel : INFO(0) zookeeper : name : join : false interval sec : 16 interval count : 512 I0902 16:09:46.970520 1678 server_util.cpp:69] load config from local file: /opt/jubatus/share/jubatus/example/config/classifier/pa1.json I0902 16:09:46.971107 1678 classifier_serv.cpp:110] config loaded: { "converter" : { "string_filter_types" : {}, "string_filter_rules" : [], "num_filter_types" : {}, "num_filter_rules" : [], "string_types" : {}, "string_rules" : [ { "key" : "*", "type" : "str", "sample_weight" : "bin", "global_weight" : "bin" } ], "num_types" : {}, "num_rules" : [ { "key" : "*", "type" : "num" } ] }, "parameter" : { "regularization_weight" : 1.0 }, "method" : "PA1" }
で、クライアントは以下のようなPythonスクリプト。 学習用のデータを定義して、それに対してテストデータを投げて男か女か判定する的な。
train_data = [
('male', datum([('hair', 'short'), ('top', 'sweater'), ('bottom', 'jeans')], [('height', 1.70)])),
('female', datum([('hair', 'long'), ('top', 'shirt'), ('bottom', 'skirt')], [('height', 1.56)])),
('male', datum([('hair', 'short'), ('top', 'jacket'), ('bottom', 'chino')], [('height', 1.65)])),
('female', datum([('hair', 'short'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.72)])),
('male', datum([('hair', 'long'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.82)])),
('female', datum([('hair', 'long'), ('top', 'jacket'), ('bottom', 'skirt')], [('height', 1.43)])),
# ('male', datum([('hair', 'short'), ('top', 'jacket'), ('bottom', 'jeans')], [('height', 1.76)])),
# ('female', datum([('hair', 'long'), ('top', 'sweater'), ('bottom', 'skirt')], [('height', 1.52)])),
]
client.train(name, train_data)
test_data = [
datum([('hair', 'short'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.81)]),
datum([('hair', 'long'), ('top', 'shirt'), ('bottom', 'skirt')], [('height', 1.50)]),
]
results = client.classify(name, test_data)
for result in results:
for r in result:
print r.label, r.score
print
実行すると、 1行目は判別が難しい、と。身長が高い女性も定義されているのでって感じですかね。 2行目はスカートってことで女性判定された感じでしょうか。
jubatus@jubatus-handson:~/jubatus-example/gender/python$ ./gender.py female 0.473417669535 male 0.388551652431 female 2.79595327377 male -2.36301612854
■ サンプルプログラムの解説 Jubatusではクライアントとサーバの間の通信にはMessagePack使ってますよーなんていう解説があった後、 サンプルプログラムが詳細に説明されていきます。 最初に、サーバーに繋げる用のインスタンスの生成のところから。
host = '127.0.0.1' port = 9199 client = jubatus.Classifier(host, port)
9199ポートは上記で接続用に設定したもので↓こんな感じ。
$ lsof -i4TCP:9199 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME jubaclass 1678 jubatus 6u IPv4 9511 0t0 TCP *:9199 (LISTEN)
・trainメソッド 分類器の学習には、「このデータはこの分類がされます」という 教師データ を与える必要があります。 この"教師データ"とかっていうのも、あんまり耳慣れない言葉だったりしますが、言い得て妙というか。 ・datumクラス コンストラクタは2つ。2つの変数はそれぞれ文字列用と数字用。 ・classifyメソッド これは結構まんまですね。 結果はclassification_resultという型のリストで返ってきて、 そこにスコアがはいっていますよ、と。 ■ サンプルの改造 上記でコメントアウトされていた2行のコメントを削除します。
19 ('male', datum([('hair', 'short'), ('top', 'jacket'), ('bottom', 'jeans')], [('height', 1.76)])),
20 ('female', datum([('hair', 'long'), ('top', 'sweater'), ('bottom', 'skirt')], [('height', 1.52)])),
一度サーバーのインスタンスを再起動します。(連続して処理を走らせると追加学習という形になるそうです)
^Cjubatus@jubatus-handson:~$ jubaclassifier -f /opt/jubatus/share/jubatus/example/config/classifier/pa1.json I0902 17:15:52.488921 2036 server_util.cpp:196] starting jubaclassifier 0.4.0 RPC server at 10.0.2.15:9199 pid : 2036 user : jubatus
再び処理を走らせると、男性を判別する精度が上がっています。
female -2.1826915741 male 3.04466104507 female 1.44372224808 male -1.01078510284
次に、男/女という括りに加えて、大人、子供というラベル(属性)を加えていきます。
train_data = [
('male(child)', datum([('hair', 'short'), ('top', 'sweater'), ('bottom', 'jeans')], [('height', 1.70)])),
('female(adult)', datum([('hair', 'long'), ('top', 'shirt'), ('bottom', 'skirt')], [('height', 1.56)])),
('male(adult)', datum([('hair', 'short'), ('top', 'jacket'), ('bottom', 'chino')], [('height', 1.65)])),
('female(child)', datum([('hair', 'short'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.72)])),
('male(adult)', datum([('hair', 'long'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.82)])),
('female(child)', datum([('hair', 'long'), ('top', 'jacket'), ('bottom', 'skirt')], [('height', 1.43)])),
#('male', datum([('hair', 'short'), ('top', 'jacket'), ('bottom', 'jeans')], [('height', 1.76)])),
#('female', datum([('hair', 'long'), ('top', 'sweater'), ('bottom', 'skirt')], [('height', 1.52)])),
]
client.train(name, train_data)
test_data = [
datum([('hair', 'short'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.81)]),
datum([('hair', 'long'), ('top', 'shirt'), ('bottom', 'skirt')], [('height', 1.50)]),
]
実行すると、ちょっと微妙な感じ。判別の難易度が上がります。
jubatus@jubatus-handson:~/jubatus-example/gender/python$ ./gender.py female(adult) -0.421601504087 female(child) 1.34721195698 male(adult) -0.171977594495 male(child) 0.108336478472 female(adult) 0.695633769035 female(child) 2.4256606102 male(adult) -1.69602179527 male(child) -0.992335438728
■ サーバーの設定変更 サーバーを立ち上げた時に設定ファイルのjsonを指定しましたが、 パラメーターを変えながら、どういう風に振るまいが変わるのか見てみよう的な。 設定項目は以下のような感じになっています。 ・converter: 特徴変換の方法 ・parameter: 学習アルゴリズムに渡すパラメータ ・method: 利用する学習アルゴリズム名 1. method 学習アルゴリズムをPA1からAROWに変えてみます。
"method" : "AROW"
サーバー上げなおして、
jubatus@jubatus-handson:~$ jubaclassifier -f myconf.json I0902 17:32:41.495383 2272 server_util.cpp:196] starting jubaclassifier 0.4.0 RPC server at 10.0.2.15:9199 pid : 2272 user : jubatus mode : standalone mode timeout : 10 thread : 2 datadir : /tmp logdir : loglevel : INFO(0) zookeeper : name : join : false interval sec : 16 interval count : 512 I0902 17:32:41.498548 2272 server_util.cpp:69] load config from local file: myconf.json I0902 17:32:41.498970 2272 classifier_serv.cpp:110] config loaded: { "converter" : { "string_filter_types" : {}, "string_filter_rules" : [], "num_filter_types" : {}, "num_filter_rules" : [], "string_types" : {}, "string_rules" : [ { "key" : "*", "type" : "str", "sample_weight" : "bin", "global_weight" : "bin" } ], "num_types" : {}, "num_rules" : [ { "key" : "*", "type" : "num" } ] }, "parameter" : { "regularization_weight" : 1.0 }, "method" : "AROW" }
教師データはちょっと戻して。
train_data = [
('male', datum([('hair', 'short'), ('top', 'sweater'), ('bottom', 'jeans')], [('height', 1.70)])),
('female', datum([('hair', 'long'), ('top', 'shirt'), ('bottom', 'skirt')], [('height', 1.56)])),
('male', datum([('hair', 'short'), ('top', 'jacket'), ('bottom', 'chino')], [('height', 1.65)])),
('female', datum([('hair', 'short'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.72)])),
('male', datum([('hair', 'long'), ('top', 'T shirt'), ('bottom', 'jeans')], [('height', 1.82)])),
('female', datum([('hair', 'long'), ('top', 'jacket'), ('bottom', 'skirt')], [('height', 1.43)])),
('male', datum([('hair', 'short'), ('top', 'jacket'), ('bottom', 'jeans')], [('height', 1.76)])),
('female', datum([('hair', 'long'), ('top', 'sweater'), ('bottom', 'skirt')], [('height', 1.52)])),
]
実行してみると、結果が変わってます。
jubatus@jubatus-handson:~/jubatus-example/gender/python$ ./gender.py female -0.170423194766 male 0.587263405323 female 0.641262471676 male -0.414164364338
2. parameter 次にサーバーの設定jsonのparameterをいじってみます。 学習そのものを制御するパラメータであるためハイパーパラメータと呼ばれることもあるそうです。
"parameter" : {
"regularization_weight" : 10.0
},
実行してみると、結果は変わりましたが、どれだけ荒くなったのかとか、トレースするのはちょっとアレですね。。
jubatus@jubatus-handson:~/jubatus-example/gender/python$ ./gender.py female -0.238820314407 male 0.688258647919 female 0.700358271599 male -0.453071296215
3. converter 最後はconverter。特徴抽出の設定。 機械学習技術では、そこに入ってくるデータは既にベクトル形式になってて〜 というのが前提的なところがあるらしいですが、そこを自分で書くのは、 自分みたいに数学が出来ない人にはしんどそうです。。 Jubatusはナマのデータを突っ込んでも大丈夫、と。 StringとNumのルールについて。 sample_weightは出現回数。binの場合、あったら1、なければ0。 global_weightは出現回数以外の重み付け。binの場合、常に1。 ベクトルの値はsample_weight×global_weightになる、と。
"string_rules" : [
{ "key" : "*", "type" : "str", "sample_weight" : "bin", "global_weight" : "bin" }
],
"num_rules" : [
{ "key" : "*", "type" : "num" }
]
次に、特徴の取り方の工夫について。
{
"名前": "山田 太郎",
"住所": "東京都 文京区 本郷"
}
さすがに本郷とかまでいくと、データとしてニッチ過ぎるよね的な。 スペース区切りにして↓こんな感じにすれば扱いやすくなりそうですね、と。
{
"名前=山田 太郎": 1.0,
"住所=東京都": 1.0,
"住所=文京区": 1.0
"住所=本郷": 1.0
}
で、先ほどの文字列ルールをスペース区切りになるように変更します
"string_rules" : [
{ "key" : "name", "type" : "str",
"sample_weight" : "bin", "global_weight" : "bin" },
{ "key" : "address", "type" : "space",
"sample_weight" : "bin", "global_weight" : "bin" }
],
こうすることによって、よりざっくり、「"東京都"は若者が多い」的なアレが出来る、と。 んな、スペースで都合良く区切られてるなんて、日本語そんなに甘くないぜ的な感じで、、 JubatusはMeCabを使って形態素解析することができる、と。 ↓設定はこんな感じ。
"string_types": {
"mecab": {
"method": "dynamic",
"path": "libmecab_splitter.so",
"function": "create",
}
},
"string_rules" : [
{ "key" : "*", "type" : "mecab", "sample_weight" : "bin", "global_weight" : "bin" }
],
最後にHTMLタグを除去したり、定形部分を削除したり、っていうクロールしてきたデータをホゲホゲする際とかに 有用そうなものも出来ちゃうのよ的な夢が広がりそうな締めくくりでございました。
機械学習とか今まで馴染みがない自分のようなエンジニアには、 使いこなすには、お勉強が必要そうな感じですが、便利そうなのは間違いないな、と。 引き続きチェックしていきたいなと思います。
![データサイエンティスト養成読本 [ビッグデータ時代のビジネスを支えるデータ分析力が身につく! ] (Software Design plus)](https://cdn-ak.f.st-hatena.com/images/fotolife/s/shinodogg/20191213/20191213131022.jpg)